
Les enjeux en instrumentation
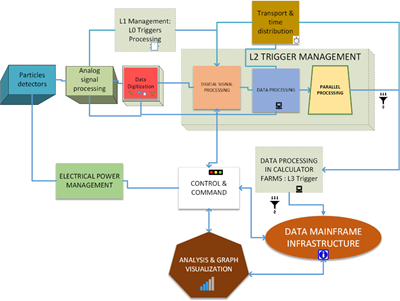
Le « dominant design » de nos instruments en recherche en physique est constitué d’une partie analogique pour chaque canal de détection, rapidement numérisé. Le traitement à ce niveau est appelé Trigger L1. On place ensuite un second niveau de concentrateur, Trigger L2 qui a accès à une partie des données des canaux de détection. En dernier lieu, l’ensemble des information issus des voies de détection peut être traité dans une ferme de calcul, trigger de niveau 3.
Dans chaque partie numérique, nous pouvons placer différentes technologies. Ainsi, au plus près des canaux, nous utiliserons plutôt des ASICs, des FPGA ou bien des circuits neuromorphiques (SNN). Au niveau L2, ce sont plutôt des FPGA, des GPU et des SNN qui pourront être envisagés. En fin, le trigger L3 utilise des CPU, des MPPA et des cartes accélératrices de calculs.
En étudiant les besoins des prochaines expériences sur accélérateurs (LHCb, ATLAS, CMS, IEC,…), un constat est le gigantisme des flux de données qui pourrait atteindre plusieurs centaines d’exaoctets par ans avec des débit de quelques 10 Téraoctets par second à plusieurs centaines de téraoctets par second. Economiquement, c’est impossible de stocker l’ensemble de ces données. Il faut donc ajouter de l’intelligence dans nos instruments, sélectionnant, réduisant la quantité d’information en temps réel à transmettre tout en conservant la qualité des données liée aux objectifs de recherche.
Un autre besoin est apparu dans le domaine de la recherche d’évènement rare comme la matière noire, l’étude des neutrinos. Il est envisageable d’optimiser l’instrument pour récupérer l’information pure du détecteur, pour sélectionner les évènements intéressants à analyser en premier.
Un domaine annexe envisageable est la maintenance prédictive des fonctions de l’instrument pour conserver une mise en opération optimale des campagnes de mesures.
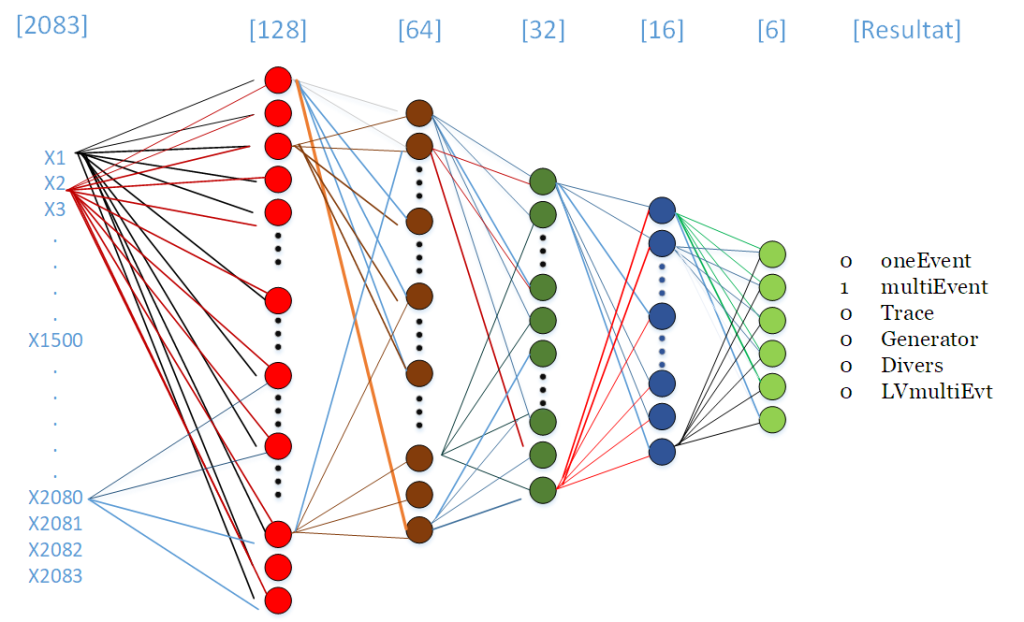
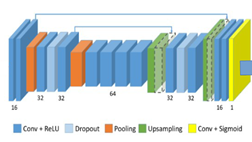

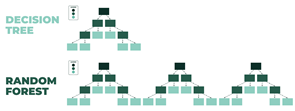
A partir des architectures de base de l’apprentissage profond, on peut envisager d’utiliser les composants type GPU, FPGA, SNN, ASICs pour résoudre un ensemble de problématique de nos instruments actuels.
Pour la simulation des instruments, on peut créer des générateurs intelligents de signaux (type GAN ou VA). Avec l’expérience acquise de la conception de grand instrument, on peut utiliser l’IA pour optimiser nos designs.
A partir du flux de données lui-même, on peut envisager d’utiliser l’IA pour la reconnaissance de signaux temporels, le recouvrement des données dû à l’empilement des signaux, l’optimisation d’instrument en pratiquant de la déconvolution au vol. Il est possible de réaliser de la sélection, de la classification des données et de la prise de décision sur les informations issues des canaux de détections. On peut envisager ensuite de réaliser de la compression de données à base d’encodeurs.
D’un côté, nous avons des technologies électroniques de plus en plus puissante en terme de calcul et de moins en moins énergivores, de l’autre, nous devons ajouter de l’intelligence dans nos instruments pour diminuer la quantité de données à stocker et/ou sélectionner les informations utiles pour nos recherches.
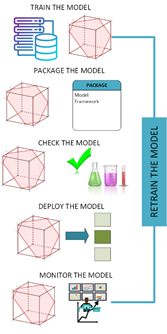
Avec les puissances de calculs des « data centers » actuelles et les modèles de machine learning que ce soit par apprentissage profond, ou par apprentissage non supervisé, ou enfin par apprentissage par renforcement, la maitrise opérationnelle ne pose pas de problème à grande échelle. Désignés sous le terme « MLOps », des frameworks applicatifs existent déjà. Mais, l’ensemble des acteurs économiques n’ont pas accès facilement à ces ressources. Par contre, l’IoT, les produits intelligents (comme la voiture autonome) vont se développer. Il y a un marché des composants intelligents de plus de 5 Milliards de dollars à la clé.
L’enjeu est donc d’évaluer chaque technologie embarquée, les outils associés et de réaliser une solution à une des problématiques citées plus haut. C’est tout l’enjeux des prochains travaux à mener pour avoir une recherche plus efficace, et moins énergivore.