
Lorsque l’on travaille avec un FPGA et que l’on souhaite exécuter un réseau de neurones deux approches sont possibles :
- Description du réseaux de neurones au sein d’un design qui est ensuite implémenté dans le FPGA. Pour exécuter des réseaux de neurones différents, il faut reprogrammer le FPGA à chaque fois.
- Description d’un processeur neuronal que l’on implémente dans le FPGA. Le processeur est par la suite capable d’exécuter différents réseaux sans que l’on ait à reprogrammer le FPGA.
Les processeurs sont grandement customisables en fonction des réseaux que l’on déploie :
- Choix des couches supportées.
- Taille des données
- Agencement des modules calculatoires (certaines configurations sont préférables pour les CNN et d’autres pour les MLP)
- Etc …
Pour le moment la solution est compatible avec les deux cartes suivantes :


Principe de fonctionnement
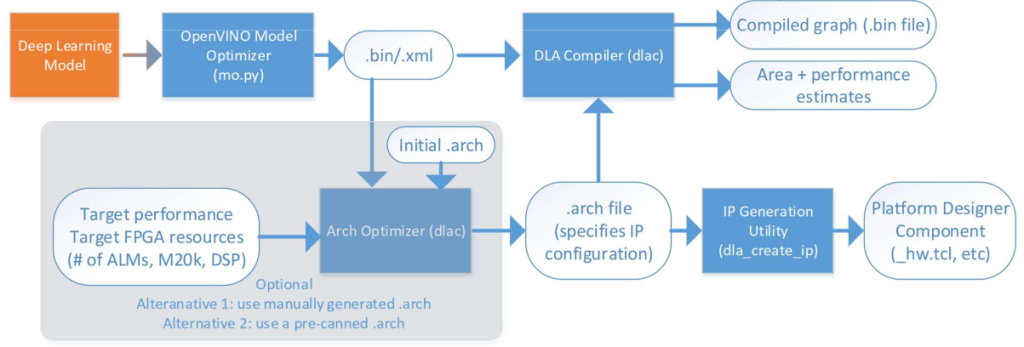
Le déploiement d’un modèle se fait en différentes étapes qui utilisent des logiciels propres :
Conversion d’un réseau avec OpenVINO
OpenVINO est un outil qui permet de prendre un modèle décrit avec les frameworks de deep learning classiques :
- Tensorflow
- Pythorch
- Caffe
- …
Puis de le convertir en ensemble de fichiers qui seront compréhensibles par le processeur neuronal que l’on aura décrit.
Le processeur neuronal
Au sein d’un fichier (.arch) on retrouve toutes les caractéristiques du processeur. Il est possible grâce à des programmes de l’optimiser en fonction de l’application que l’on cible.
Une fois que le processeur est convenable, un programme permet de générer un bitstream.
Enfin, à l’aide d’une commande particulière on programme le FPGA avec le bitstream généré.
Inférence
Au sein de FPGA AI Suite, l’outil benchmark_app permet de réaliser l’inférence de réseaux neuronaux et de récupérer les données relatives aux performances d’exécutions.
Il existe 2 modes d’inférence différents :
- Just-In-Time : Le réseau est compilé au moment de l’inférence.
- Ahead-of-Time : Le réseau a été compilé au préalable.
Voici sous forme de graphique le workflow d’Intel Ai Suite :
Performances sur les réseaux challenges
Les performances qui suivent sont données en fonction de 3 paramètres que l’on fait varier au fils des inférences :
- -niter : Nombre d’entrées à traiter.
- -nireq : Nombre d’exécutions en parallèle (sous multiple de niter).
- -api : Mode dans lequel on utilise l’API (async ou sync).
| -api | -niter | -nireq | FPS JIT | FPS AOT |
| async | 12 | 6 | 14 046 | 6 650 |
| async | 12 | 4 | 13 982 | 7 252 |
| async | 12 | 3 | 11 505 | 6 477 |
| async | 12 | 2 | 9 752 | 6 073 |
| async | 12 | 1 | 6 484 | 4 391 |
| sync | 12 | X | 13 056 | 8 704 |
| -api | -niter | -nireq | FPS JIT | FPS AOT |
| async | 12 | 6 | 18 489 | 7 245 |
| async | 12 | 4 | 15 003 | 7 503 |
| async | 12 | 3 | 14 003 | 6 525 |
| async | 12 | 2 | 13 514 | 5 747 |
| async | 12 | 1 | 6 178 | 4 198 |
| sync | 12 | X | 16 316 | 10 294 |
| -api | -niter | -nireq | FPS JIT | FPS AOT |
| async | 12 | 6 | 14 053 | 8 400 |
| async | 12 | 4 | 11 848 | 7 643 |
| async | 12 | 3 | 10 987 | 7 576 |
| async | 12 | 2 | 8 225 | 5 925 |
| async | 12 | 1 | 6 178 | 5 421 |
| sync | 12 | X | 9 224 | 7 711 |
| -api | -niter | -nireq | FPS JIT | FPS AOT |
| async | 12 | 6 | 18 662 | 7 498 |
| async | 12 | 4 | 13 506 | 6 903 |
| async | 12 | 3 | 13 450 | 6 281 |
| async | 12 | 2 | 11 075 | 5 852 |
| async | 12 | 1 | 6 317 | 4 116 |
| sync | 12 | X | 14 023 | 9 596 |
Conclusion
Avantages :
- Ne nécessite pas d’apprendre de nouveaux frameworks : utilisation de modèles Keras, Pytorch etc…
- Optimisation du processeur en fonction de l’application.
- Programmation statique du bitstream relatif au processeur puis exécution dynamique des réseaux.
inconvénients :
- Technologie en développement : supportée pas 2 cartes spécifiques.
- Nécessite une configuration particulière : Ubuntu 18.04, 48 Gb de RAM.