
La programmation d’un FPGA peut se faire de différentes manières ainsi qu’à différents niveaux :
- Bas niveau : Description du fonctionnement voulu à bas niveau en VHDL/Verilog.
- Plus haut niveau : Utilisation d’IP propriétaires intégrées au sein d’un design.
- Encore plus haut niveau : Génération d’IP à l’aide du moteur de compilation High Level
Synthesis (HLS) d’Intel (programmation en C++).
En utilisant Intel HLS, on accepte de perdre un peu de contrôle sur ce qui est généré au niveau RTL au profit d’un temps de développement nettement réduit.
Principe de fonctionnement
Le développement HLS se fait au niveau software, pas besoin d’avoir de compétences particulières en électronique pour s’approprier l’outil :
- Développement en C++ légèrement revisité.
- Intel HLS s’utilise uniquement en ligne de commande (commande i++).
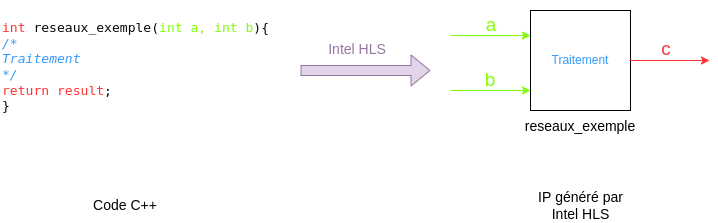
Du code c++ à l’IP
Voici une analogie entre le code écrit et ce qui est généré in fine :
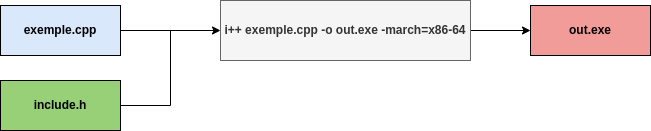
Compilations avec i++
i++ est le pendant de g++ mais appliqué à la génération d’IP intégrable dans quartus.
Il existe 2 modes de fonctionnements distincts :
- Une compilation pour le débogage : permet de vérifier le bon fonctionnement du composant décrit (possibilité d’utiliser des outils comme printf, cout ou gdb).
Le graphique ci-dessus décrit une manière simple d’utiliser le mode de débogage :
- Une compilation qui cible un FPGA : Une fois que le composant fonctionne correctement on synthétise un « projet » c’est à dire une suite de dossier contenant l’IP, les rapports, les simulations etc.. :
Le graphique ci-dessus décrit une compilation qui cible un FPGA Arria 10 :

Optimisations du code
Un réseau de neurones est composé de très nombreux neurones agencés en couches. Lorsque l’on va décrire tout cela en C++ il va falloir porter une attention toute particulière à différents points :
- La taille des variables que l’on manipule : Intel HLS met à notre disposition des types particuliers (ac_fixed, ac_int), ils permettent de gérer très précisément le nombre de bits alloués à tel ou tel paramètre.
- La manière de décrire les boucles de calculs : Afin d’obtenir un code optimisé, Intel a établi une liste des pièges à éviter ainsi qu’un guide des bonnes pratiques de codages. En effet, bien que l’on travaille en C++ c’est du code VHDL/Verilog qui est généré.
- Utilisation des pragmas : Il est possible de contraindre l’exécution d’une boucle de telle ou telle manière. Pour cela, il faut placer un petit morceau de code en entête de la boucle (c’est ce qu’on appelle les pragmas).
Performances sur les réseaux « challenges »
Les résultats présentés ci-dessous sont le fruit de 4 implémentations différentes (horloge à 240MHz) :
- Vanilla : Une implémentation qui ne contient pas d’optimisations dans le code.
- Pipeline : Une implémentation dans laquelle on pipeline le réseau.
- Unroll : Une implémentation dans laquelle on unroll la totalité des boucles.
- U+p : Une implémentation dans laquelle on unroll une partie des boucles (les boucles imbriquées) + pipeline du réseau.
| ALUTS | FFs | RAMs | MLABs | DSPs | Débit (FPS) | |
| Ch1 vanilla | 602 | 547 | 4 | 2 | 1.5 | 5 217 391 |
| Ch1 pipeline | 610 | 624 | 4 | 5 | 1.5 | 26 666 667 |
| Ch1 unroll | 515 | 245 | 4 | 1 | 0 | 240 000 000 |
| Ch1 u+p | 515 | 245 | 4 | 1 | 0 | 240 000 000 |
| ALUTS | FFs | RAMs | MLABs | DSPs | Débit (FPS) | |
| Ch3 vanilla | 1 408 | 1 809 | 30 | 12 | 2.5 | 9 383 |
| Ch3 pipeline | 2 093 | 4 460 | 32 | 48 | 2.5 | 11 988 |
| Ch3 unroll | 118 041 | 36 737 | 5 | 37 | 0 | 240 000 000 |
| Ch3 u+p | 27 524 | 42 546 | 1 855 | 298 | 75 | 2 376 237 |
| ALUTS | FFs | RAMs | MLABs | DSPs | Débit (FPS) | |
| Ch4 vanilla | 4 442 | 6 415 | 355 | 20 | 3.5 | 364 |
| Ch4 pipeline | 5 555 | 10 899 | 362 | 113 | 3.5 | 480 |
| Ch4 unroll | XXXX | XXXX | XXXX | XXXX | XXXX | XXXX |
| Ch4 u+p | XXXX | XXXX | XXXX | XXXX | XXXX | XXXX |
| ALUTS | FFs | RAMs | MLABs | DSPs | Débit (FPS) | |
| Ch5 vanilla | 1 669 | 2 193 | 32 | 16 | 2.5 | 2 556 |
| Ch5 pipeline | 2 617 | 6 074 | 35 | 76 | 2.5 | 3 839 |
| Ch5 unroll | 569 249 | 196 051 | 6 | 40 | 0 | 240 000 000 |
| Ch5 u+p | 17 560 | 23 244 | 507 | 237 | 50.5 | 952 380 |
Conclusion
Avantages :
- Permet d’attendre des débits très élevés : sur des réseaux petits ou bien optimisés.
- Possibilité d’implémenter facilement des réseaux en parallèle sur un FPGA : en effet, ce sont des IP qui sont facilement interfaçable en parallèle au sein d’un même design.
- Il est beaucoup plus facile de voir l’influence de tel ou tel paramètre avec HLS qu’avec du VHDL/Verilog classique : une compilation peut prendre du temps mais changer une ligne de code reste beaucoup plus simple que de réécrire du code VHDL/Verilog.
- Les test/simulations sont aussi grandement facilités : Le main du code C++ devient le testbench du composant. Beaucoup plus simple d’exécuter un programme que de faire des simulations Quartus.
Inconvénients :
- Perte de contrôle sur ce qui est généré au final : même en utilisant tous les outils à notre disposition il n’est pas possible d’écrire un code aussi optimisé que ce que nous pouvons réaliser en VHDL/Verilog.
- Il est possible d’avoir des mauvaises surprises lors de la synthèse des projets : la compilation x86-64 et la compilation pour un FPGA peuvent donner des résultats différents lors de l’exécution. Pour éviter cela, il est conseillé de suivre les recommandations fournies par Intel.
- Une méthode adaptée pour les réseaux simples et de petites tailles : pour les réseaux plus conséquents (traitement d’images), privilégier des solutions adaptées (Brainchip, Vitis AI, FPGA AI Suite)