
La société Brainchip commercialise depuis peu des processeurs neuronaux. Ils comportent 1,2 million de neurones et 10 milliards de synapses répartis autour de 80 Neural Processing Units (NPUs).
Pour le moment, nous avons utilisé leur solutions PCIe nommée AkidaTMPCIe Board :

Le chip que l’on voit sur la AkidaTMPCIe Board est un AKD1000 :
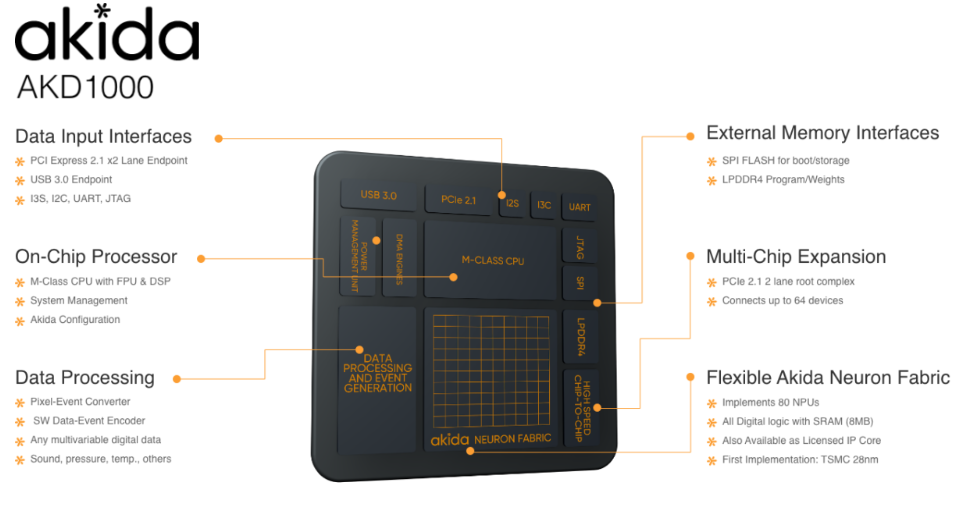
Cette technologie vise à remplacer dans certains domaines l’utilisation du cloud. Le fait de traiter les données en local au niveau hardware au plus près du capteur présente plusieurs avantages :
- Economie d’énergie : La puce Akida traite des réseaux de neurones à événements discrets ( des Spiking Neural Networks ) qui lui permette d’être efficace au niveau énergétique.
- Sécurité accrue : Le traitement en local de données sensibles réduit le risque que ces dernières soient récupérées par une personne tiers.
- Plus efficace : Ne pas avoir à échanger de données entre le capteur et le cloud permet de diminuer la latence de traitement.
Il est possible de programmer plusieurs réseaux en simultanés sur la puce.
Principe de fonctionnement
Nous utilisons pour le moment la version PCIe de la puce. Afin de dialoguer avec tout se passe en Python. Des bibliothèques spécifiques sont mises à notre disposition par Brainchip. Le fonctionnement est grandement inspiré de Tensorflow Keras :

Le développement se déroule en plusieurs étapes, la première étape consiste à convertir un réseau classique en réseau compatible avec la carte :
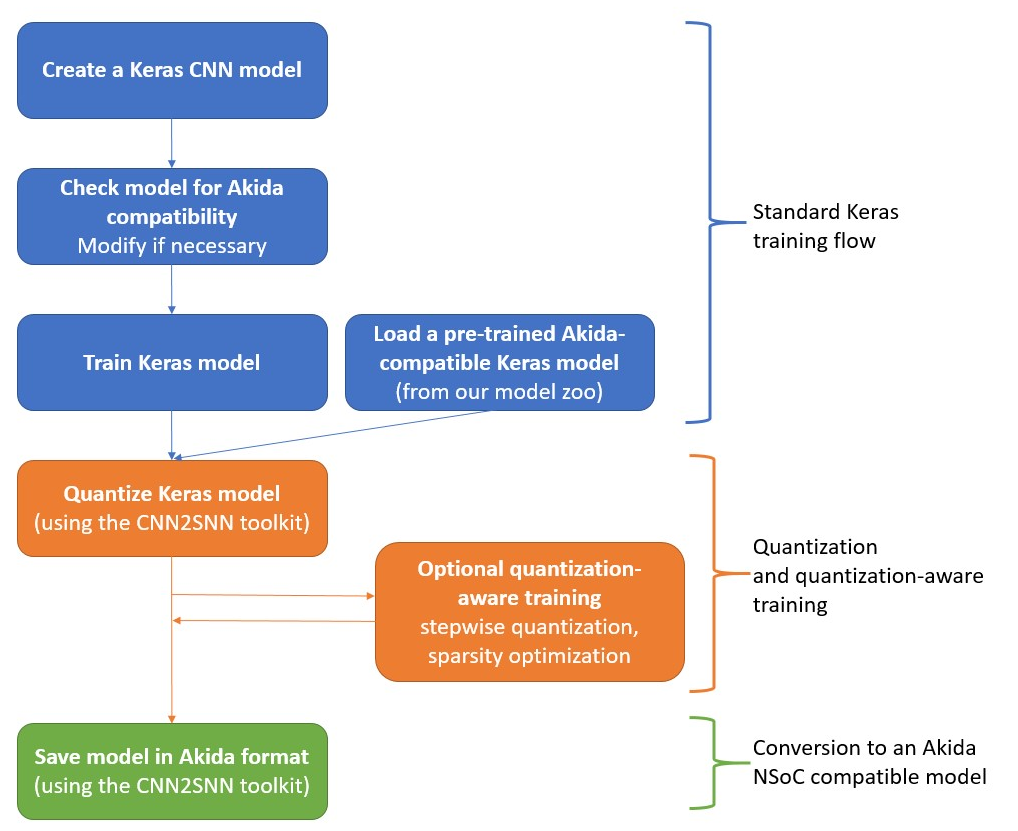
Une fois que l’on a un modèle au bon format on peut réaliser l’inférence de données.
Performances sur les réseaux « challenges »
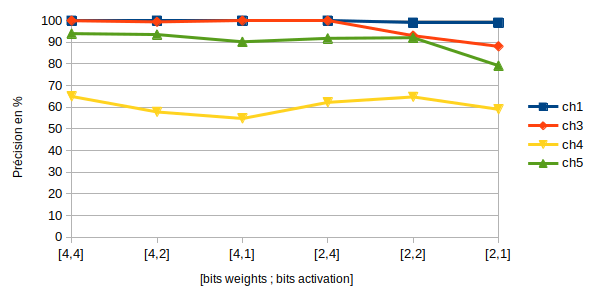
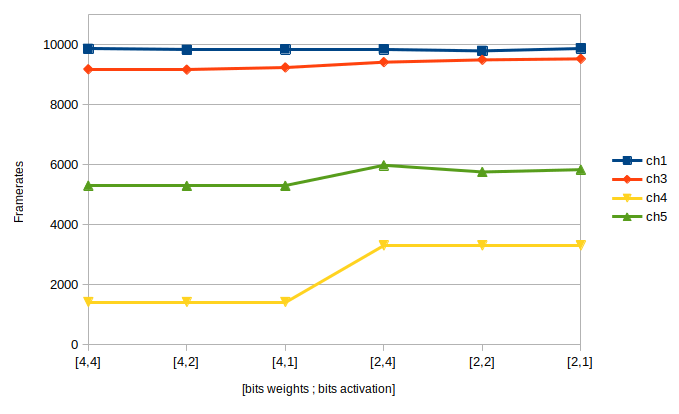
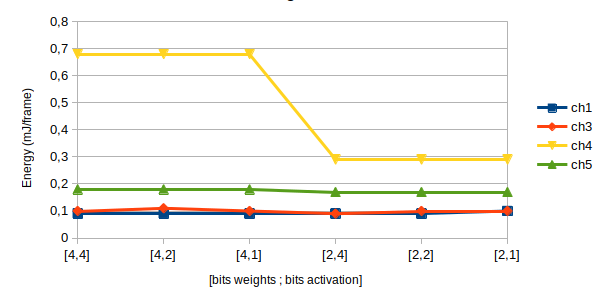
La taille des données est un paramètre extrêmement important lorsque l’on travaille avec la puce Akida.
Les résultats sont donnés en fonction du nombre de bits des poids (weight_q) et du nombre de bits en sortie des couches d’activation (activ_q).
Précision
Données traitées par seconde (FPS)
Consommation Énergétique
Conclusion
Avantages :
- Énormément de ressources : 1,2 million de neurones et 10 milliards de synapses
- Une utilisation intuitive dès lors que l’on connait Keras: Une documentation fournie https://doc.brainchipinc.com/.
- Faible consommation énergétique.
- Une technologie qui évolue : Brainchip travaille actuellement sur la Akida 2.0 qui devrait supporter d’avantages de réseaux.
Inconvénients :
- L’utilisation des NPUs : Un même NPU ne peut pas être assigné à l’exécution de plus d’une couche. De nombreux neurones et synapses restent la plupart du temps inutilisés et ce, même lorsque l’on implémente un design utilisant les 80 NPUs.
- Faible bande passante en entrée : PCIe gen2 x1 : 4Gb/s
- Des tailles de données en entrées très limitées : 8 bits avec une couche convolutive en entrée , 4 bits autrement.
- Peu de couches supportées pour le moment.
- Une architecture pensée pour le traitement d’images.