
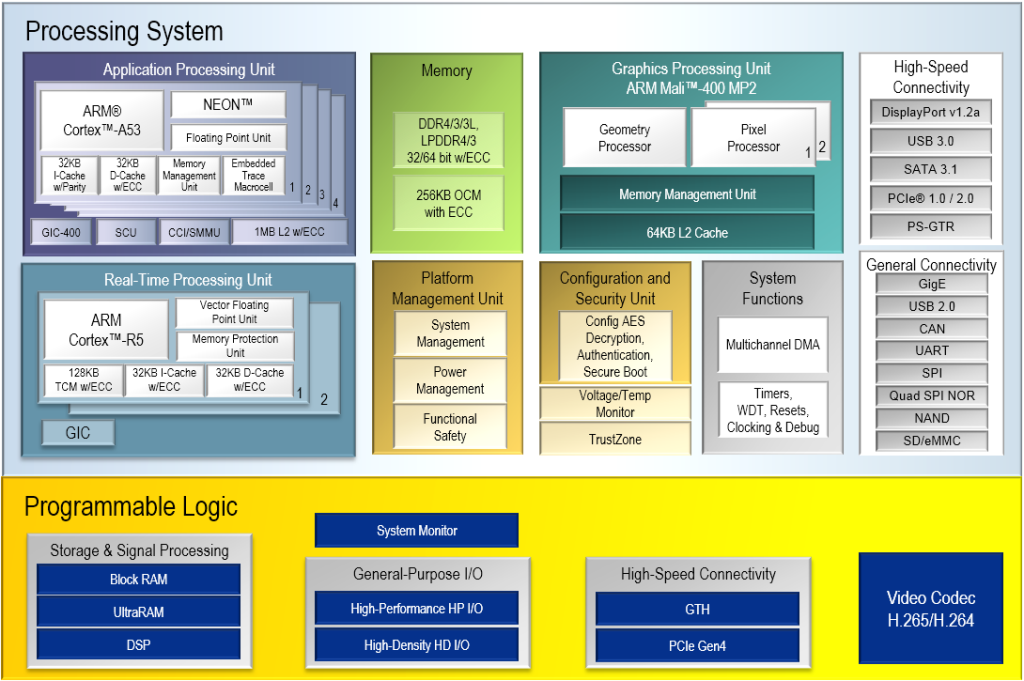
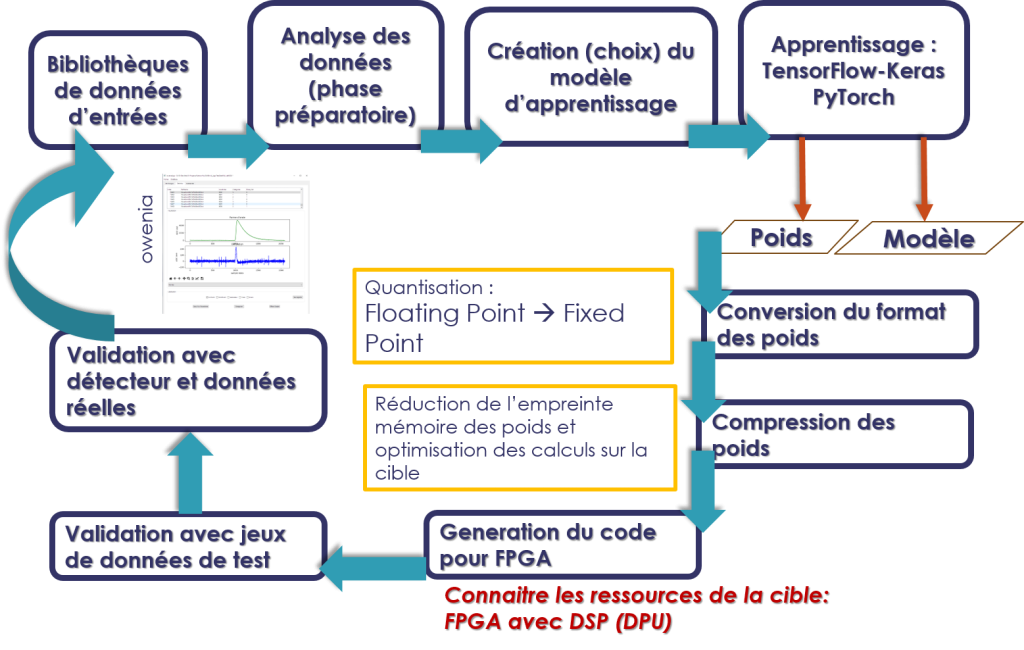
Le System-On-Chip Zynq est un système comportant une partie de programmation logique et un ensemble de processeurs. Les differentes parties communiquent entre elles grâce à un ensemble de bus point à point (Advanced eXtensible Interface). La partie logique contient des composants BRAMs, LUT (Look-up tables) et DSPs (Digital Signal Processors) en grands nombres. Le composant permet de construire en firmware des algorithmes avancés comme les réseaux de neurones profonds.


Le flot de programmation du Zynq
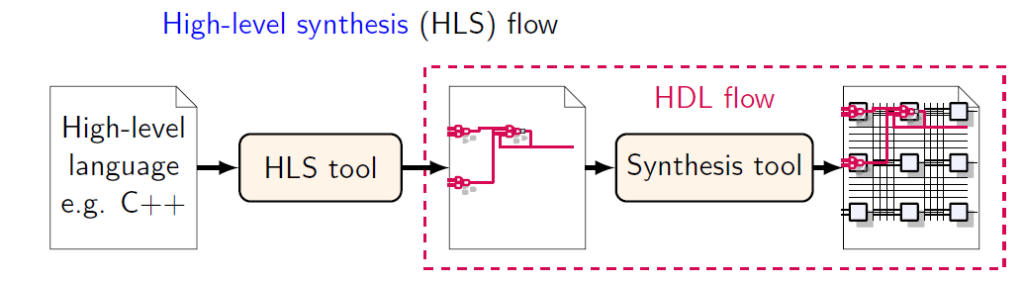
La programmation des composants logiques peut se faire à partir d’un langage de description matériel comme le VHDL ou le Verilog. L’outil VIVADO permet de réaliser la synthése et le routage sur le circuit cible. Avec VIVADO_HLS, l’utilisation du langage C++ et ses directives de compilations (#PRAGMA) permet d’implémenter directement le code VHDL ou Verilog, prêt à être utiliser dans un système sous forme d’IP.
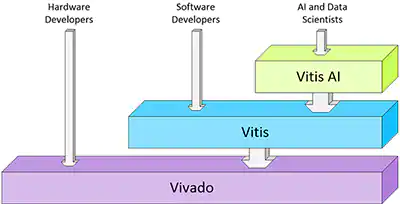
A partir du circuit logique et des processeurs embarqués dans le Zynq, la suite logiciel VITIS_ML permet d’implémenter un OS, de réaliser les applications logicielles associées au circuit.
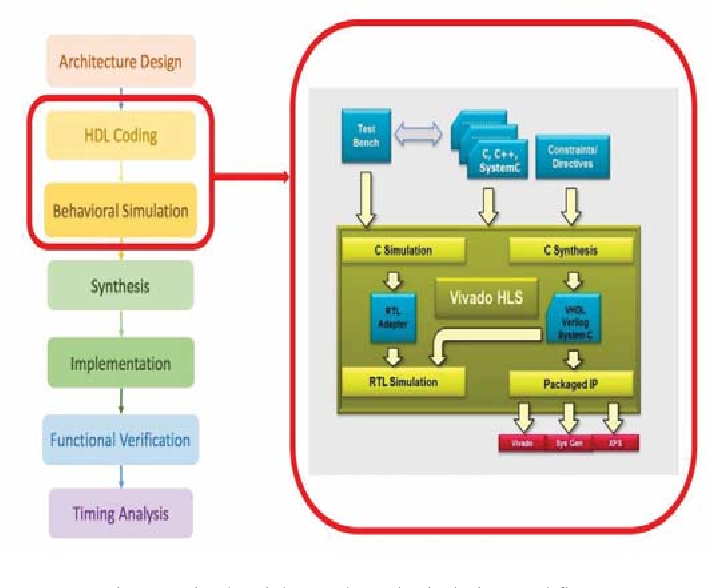
Le flot de conception d’un réseau de neurones dans un FPGA
Les outils à installer :
- Linux (Ubuntu, CentOS)
- GCC / C++ (yum install gcc-c++)
- Graphviz ( yum install graphviz )
- VIVADO HLS (6h d’installation) version 2019.2
- ANACONDA (plateforme python ) :
- Jupyter lab
- Tensorfloaw & Keras
- QKeras
- pyTorch
- pyQt5
- pyDot
- HLS4ML
Etapes de modélisation du réseau de neurones :
- Créer le modèle
- Définir une fonction d’évaluation (dans notre cas, nous utilisons l’algorithme « adam » avec la fonction de perte « crossentropy »)
- Entrainement du modèle
- Optimisation avec GridSearchCV (facultatif)
- Analyse des erreurs et retour au Preprocessing / EDA
- Learning Curve et prise de décision
Utilisation de HLS4ML et Tensorflow_optimizer
Pour intégrer les nombreux neurones dans un FPGA, il faut essayer d’optimiser le circuit en reduisant le nombre de ressources du FPGA en termes de RAM, LUT et DSP. Pour cela, il y a plusieurs paramètres à analyser :
- Les #PRAGMA HLS :
- Unrolling – séquentiel- Optimisation en ressources (resource)
- Pipeline – parallélisme – Optimisation en temps (latence)
- Reduction du nombre de coefficients du réseau – Elagage- -Pruning-
- librairie « Tensorflow-model-optimization »,
- Reduction de dimension du codage des valeurs -quantification-
- Passage de nombre à virgule flottante en nombre à virgule fixe
- HLS4ML configuration
- Modèle QKeras
- Passage de nombre à virgule flottante en nombre à virgule fixe
Les étapes de compression de l’information pour FPGA sont :
- Connaitre les spécificités du FPGA (nombre de LUT/DSP, dimension des entrées)
- Etude de l’échelle des ensembles des coefficients du réseau. (HLS4ML)
- Elagage des coefficients
- Quantification des valeurs pour diminuer l’empreinte dans le FPGA.
Génération du code VHDL avec VIVADO_HLS :
HLS4ML permet de compiler le modèle créé en python et d’avoir en sortie le code HLS (C++ et #pragma) suivant les options de configuration définit dans le script python. VIVADO_HLS va permettre d’implementer ce code en VHDL ou Verilog. L’utilisateur va également pouvoir faire évoluer les directives de compilations pour réorganiser l’interface des entrées et des sorties, décider de la politique Unroll/pipeline etc…
VIVADO_HLS donnera un rapport concernant les ressources, les temps de latences du circuit conçu en VHDL.
Application à des réseaux de neurones de test : les challenges
Parce que nous voulons comprendre les étapes de conversion d’un modèle de réseaux de neurones pour l’intégration dans un FPGA, nous avons créé des « challenges », réseaux de neurones avec des entrées simples mais un nombre de neurones croissant selon la répartition des données d’entrées.
Il s’agit d’un reseau de neurone qui, à partir d’une coordonnée (x,y), classe le point dans une région d’un espace à deux dimensions. La forme de cette espace est plus ou moins complexe.
Les entrées ont les caractéristiques suivantes :
- X / X ∈ [0,1]
- Y/ Y ∈ [0,1]
La sortie est telle que :
- S / S ∈ {0, 1} ; 0 et 1 désignant une ou l’autre des régions.
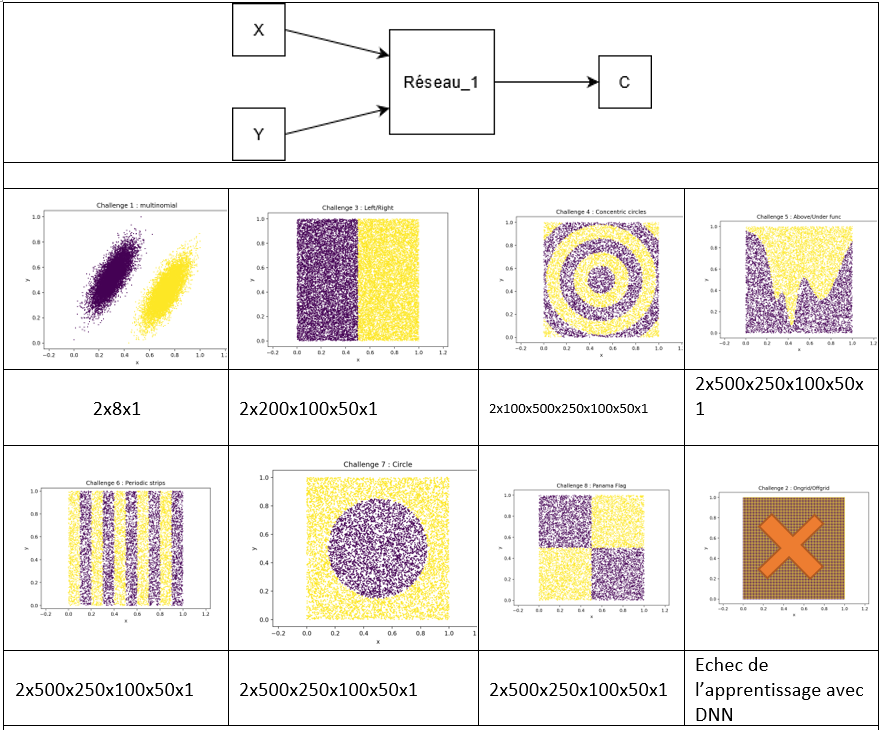
Nous avons étudié les challenge CH1, CH3, CH4, CH5 et CH7 pour l’intégration sur la plateforme ZCU102 de AMD-Xilinx. Nous avons testé une modélisation classique avec Keras et avec QKeras d’un reseau de neurone profond. Nous avons également mis en œuvre l’élagage du reseau à l’aide des outils tensorflow-keras-optimization. QKeras prend en charge des fonctions d’activation simple comme quantized_relu, quantized_tanh. La suite du développement est d’utiliser le framework HLS4ML pour créer le modèle HLS du réseau et lancer la synthèse en vhdl. En regardant les fichiers textes stockant les poids des différents neurones, on constate la mise à zéro de différents poids du réseau.
Nous avons utilisé les 5 challenges CH1, CH3, CH4, CH5, CH7 pour tester les étapes de créations de modules VHDL implémentables dans un MPSoc Zynq. Nos cibles sont une carte ARTY Z7 et ZCU102. En réalisant les tests sur les différents challenges, on constate, dans le tableau ci-dessous, les situations suivantes :
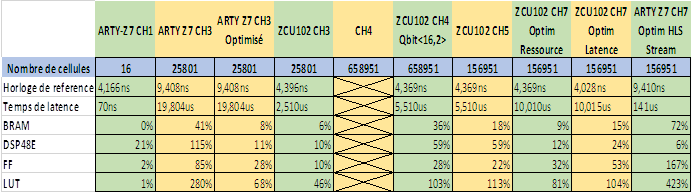
Sans optimisation par élagage et quantification des coefficients, quelques milliers de poids dans un réseau de neurones suffisent à dépasser les capacités du Zynq020 de la carte ARTY Z7. Il faut passer à un composant beaucoup plus riche en ressources comme la ZCU102. Dans ce cas, nous nous retrouvons bloquer.
Nous pouvons alors tester les techniques de réduction de l’empreinte en utilisant l’élagage et la quantification avec HLS4ML ou QKeras.
On peut constater que ce n’est pas suffisant pour avoir un modèle intégrable dans un composant même avec beaucoup de ressource. En effet, on constate que le nombre LUT explose. Pourquoi cette situation apparaît alors que nous avons essayé de diminuer l’empreinte de notre modèle d’IA ?
Cela vient de l’implémentation et de la synthèse du réseau par VITIS HLS. En fait, pour essayer d’optimiser la rapidité des calculs à travers les DSP des composant, HLS4ML utilise un pragma :
#pragma HLS ARRAY_PARTITION variable=layer2_out complete dim=0
Conclusion
En utilisant les outils tensorflow/Keras, le framework HLS4ML et QKERAs, nous parvenons à descendre un réseau de neurones dans un FPGA Zynq de Xilinx. Il faut également optimiser le code HLS en sélectionnant les pragma utiles. La méthodologie a été validée. Il faut optimiser le réseau par rapport à la problématique. Le point faible est la création de l’interface d’entrée par VIVADO HLS qui, pour l’instant, ne permet pas de gérer des matrices directement.